书到用时方恨少,训练慢时恨卡少。不过混合精度训练可以带来30%以上的up体验(Mixed Precison Training)
一、apex用法
- O0:单精度fp32
- O3:半精度fp16
- O1:mix precision(recommand)
- O2:almost fp16
二、torch 1.6内置用法
from torch.cuda.amp import GradScaler,autocast
scaler = GradScaler()
with autocast():
output = model(input)
loss = loss_fn(output, target)
scaler.scale(loss).backward()
scaler.step(optimizer)
scaler.update()三、主要步骤
- Mix Precision
- 根据预设的黑白名单,对算子选择是否混合精度计算:乘法计算采用fp16,加法累加采用fp32
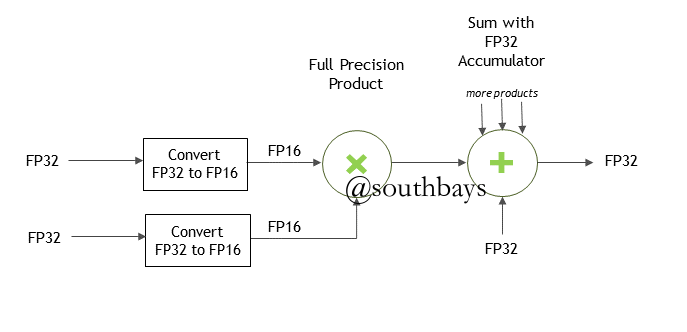
- 根据预设的黑白名单,对算子选择是否混合精度计算:乘法计算采用fp16,加法累加采用fp32
- Loss Scaling
- 在计算loss时适当放大loss,在优化器更新参数时缩小同样倍数梯度。目前apex支持动态放缩倍数。
四、loss scale的思想
在交易系统中算钱的时候,规范的做法是把金额如1.01元*100之后再做计算,计算完之后再除以100,这样可以避免0.01无法用二进制精确表示造成的舍入误差
怎么用好loss scale
理想情况(来自官方文档)
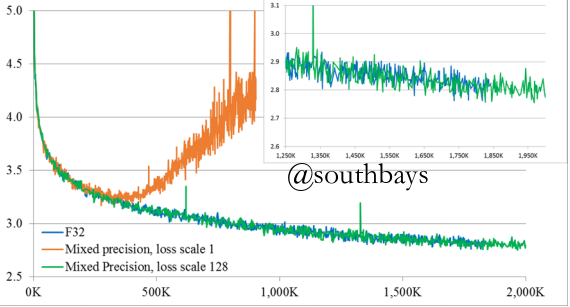
现实(动态loss scale梯度爆炸)
Gradient overflow. Skipping step, loss scaler 0 reducing loss scale to 32768.0
Gradient overflow. Skipping step, loss scaler 0 reducing loss scale to 16384.0
Gradient overflow. Skipping step, loss scaler 0 reducing loss scale to 8192.0
Gradient overflow. Skipping step, loss scaler 0 reducing loss scale to 4096.0
Gradient overflow. Skipping step, loss scaler 0 reducing loss scale to 2048.0
...
Gradient overflow. Skipping step, loss scaler 0 reducing loss scale to 1.0
...
Gradient overflow. Skipping step, loss scaler 0 reducing loss scale to 0.00048828125
Gradient overflow. Skipping step, loss scaler 0 reducing loss scale to 0.000244140625
Gradient overflow. Skipping step, loss scaler 0 reducing loss scale to 0.0001220703125
Gradient overflow. Skipping step, loss scaler 0 reducing loss scale to 6.103515625e-05
Gradient overflow. Skipping step, loss scaler 0 reducing loss scale to 3.0517578125e-05五、踩坑心得
- 可以不用loss scale,直接走loss.backward(),根据收敛情况调节学习率,实测bert微调ner时学习率需要调大一点(建议10倍往上调),不过确实精度会差几个点
- 论文原话:We trained a variety of networks with scaling factors ranging from 8 to 32K(many networks did not require a scaling factor)
- loss scale时梯度偶尔overflow可以忽略,因为amp会检测溢出情况并跳过该次更新(如果自定义了optimizer.step的返回值,会发现溢出时step返回值永远是None),scaler下次会自动缩减倍率,如果长时间稳定更新,scaler又会尝试放大倍数
- 一直显示overflow而且loss很不稳定的话就需要适当调小学习率(建议10倍往下调),如果loss还是一直在波动,那可能是网络深层问题了。
六、实验数据
bert微调ner的小实验,相同batch size和epoch,在挑战集评测结果
| name | 初始学习率 | f1 | p | r | 显存占用 | 相对速度 |
|---|---|---|---|---|---|---|
| fp32 | 1e-5 | 0.991 | 0.992 | 0.989 | 9097M | 5.4 |
| amp no scale | 10e-5 | 0.953 | 0.963 | 0.943 | 7523M | 7.0 |
| amp dynamic scale | 0.1e-5 | 0.962 | 0.968 | 0.955 | 7523M | 7.0 |
tensorflow开启混合精度(nvidia开发者文档)
import os
os.environ['TF_ENABLE_AUTO_MIXED_PRECISION'] = '1'
optimizer = tf.train.experimental.enable_mixed_precision_graph_rewrite(optimizer)