经过几天的奋战,终于完成tensorrt的官方文档的梳理并实现了基于pycuda的后端部署,
因为python相关资料确实少,所以想分享一下自己的经验。首先总结一下tensorrt的三个特性
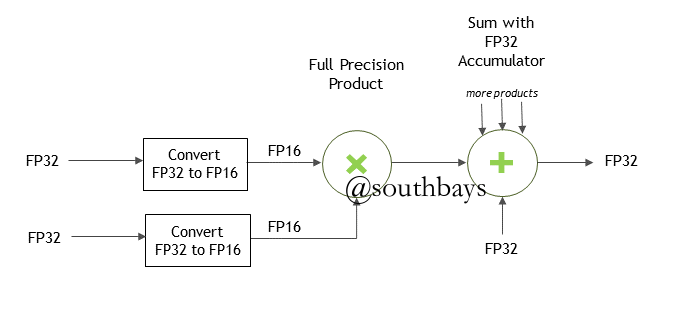
- 速度就是正义:GPU相对加速50%以上。半精度和int8加持可以翻倍,官方案例TensorRT 8,BERT-Large推理仅需1.2毫秒!(只支持GPU,因为运行需要特定的算子kenel,被一些文章误导了很久,笔者有误必勘,欢迎大家指正)
- 通用性:支持多深度学习框架,目前最流行torch->onnx->tensorRT,tf原生支持(pb->tf-trt,如果trt没有的算子就会用tf自带的算子替代,速度比纯trt要慢一些)
- 定制性:tensorrt根据不同显卡定制优化引擎,同等计算能力才能勉强兼容,而且同一型号显卡如果显存和gpu核心时钟频率不一致也会对性能造成影响。tf2onnx
一、tensorrt workflow
tensorrt runtime api的核心是trt engine和trt context(这里和cuda context管理区分开)
官方工作流程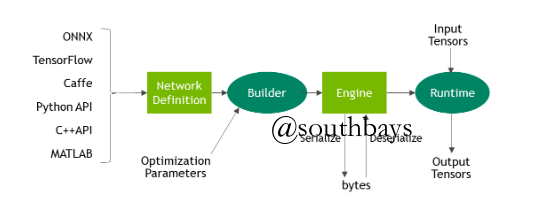
实战编码流程:Builder->Network->Parser/Self define->Engine->Context->Cuda coding
二、tensorrt(7+) Dynamic Shapes
6以上支持batch,7以上支持batch和动态尺寸,8以上支持更多onnx算子(如gather elements),这点和onnx一样,向下兼容性做的比较好
- explicit batch dimension
- Python
create_network(1 <<int(tensorrt.NetworkDefinitionCreationFlag.EXPLICIT_BATCH))
- Python
- runtime dimension 动态的维度用-1表示。从onnx解析的network会自动推测动态的维度。
- buildtime dimension build engine时指定optimization profiles来设置动态tensor形状的范围
- use engine
a. Create an execution context from the engine, the same as without dynamic shapes.
b. Specify one of the optimization profiles from step 3 that covers the input dimensions.
c. Specify the input dimensions for the execution context.
d. Enqueue work.
runtime dimension
- if define a network from scrach,input and output shapes should be specified
- if network is parsed from onnx or other,shapes can be infered automatically
- python
# when defining a network yourself network_definition.add_input("foo", trt.float32,(3, -1, -1)) # at runtime context.set_binding_shape(0, (3, 150, 250)) engine.get_binding_shape(0) # returns (3, -1, -1). context.get_binding_shape(0) # returns (3, 150, 250).
buildtime dimension
- python
# at least one profile should be specified # minimum size of [3,100,200], a optimization size of [3,200,300], and maximum dimensions of [3,150,250] profile = builder.create_optimization_profile(); profile.set_shape("foo", (3, 100, 200), (3, 150, 250), (3, 200, 300)) config.add_optimization_profile(profile)
三、engine and context
docker环境配置 cuda10.2-python3.6-trt8
FROM nvidia/cuda:10.2-cudnn8-devel-ubuntu18.04
ENV TRT_VERSION=8.0.1.6 \
TRT_HOME=/usr/local/Tensorrt \
CUDA_HOME=/usr/local/cuda \
LIBRARY_PATH=/usr/local/cuda/lib64 \
LD_LIBRARY_PATH=/usr/local/Tensorrt/lib:/usr/local/cuda/lib64
# 需要下载tensorrt对应版本的压缩包解压到当前目录
COPY . /usr/local/Tensorrt-$TRT_VERSION/
RUN ln -s /usr/local/Tensorrt-$TRT_VERSION /usr/local/Tensorrt \
&& pip install $TRT_HOME/python/tensorrt-$TRT_VERSION-cp36-none-linux_x86_64.whl
# start
# docker run -it --gpus all cuda10.2-python3.6-trt8 bashtrt engine
def build_or_create_engine(onnx_path, trt_path, input_optimitions=None, max_batch_size=1, save_engine=1,
re_build=0):
TRT_LOGGER = trt.Logger()
EXPLICIT_BATCH = 1
if os.path.exists(trt_path) and not re_build:
with trt.Runtime(TRT_LOGGER) as runtime, open(trt_path, 'rb') as f:
engine = runtime.deserialize_cuda_engine(f.read())
print('deserialized trt engine from file')
return engine
with trt.Builder(TRT_LOGGER) as builder, builder.create_network(EXPLICIT_BATCH) as network, \
builder.create_builder_config() as config:
if not os.path.exists(onnx_path):
quit('onnx file {} not found'.format(onnx_path))
with trt.OnnxParser(network, TRT_LOGGER) as parser, open(onnx_path, 'rb') as model:
print('parsing onnx file {}'.format(onnx_path))
if not parser.parse(model.read()):
print('ERROR: Failed to parse the ONNX file.')
for error in range(parser.num_errors):
print(parser.get_error(error))
return
builder.max_batch_size = max_batch_size
config.max_workspace_size = 1 << 30
profile = builder.create_optimization_profile()
[profile.set_shape(*s) for s in input_optimitions]
config.add_optimization_profile(profile)
print('building an engine from file {}; this may take a while...'.format(onnx_path))
engine = builder.build_engine(network, config)
if not engine:
print("tensorRT engine built failed")
else:
print("tensorRT engine built success")
if save_engine:
with open(trt_path, "wb") as f:
f.write(engine.serialize())
print('tensorRT engine saved')
return enginetrt context
def allocate_buffers_and_inference(context, engine, trt_inputs: list = None):
"""
allocate cpu and gpu buffer of inputs and outputs,
init bindings of gpu memory and cuda stream
:param context: trt context
:param engine: trt engine
:param trt_inputs: a list of real input, which is type of numpy array
:return: inputs, outputs, bindings, stream
"""
if trt_inputs and trt_inputs[0]:
real_size = min(engine.max_batch_size, len(trt_inputs[0]))
trt_inputs = trt_inputs[: real_size]
else:
real_size = engine.max_batch_size
print('batch size %d' % real_size)
inputs = []
outputs = []
bindings = []
for i, binding in enumerate(engine):
print(binding, engine.get_binding_shape(binding))
size = abs(trt.volume(engine.get_binding_shape(binding))) * real_size
dtype = trt.nptype(engine.get_binding_dtype(binding))
# Allocate host and device buffers
host_mem = cuda.pagelocked_empty(size, dtype) if not trt_inputs else trt_inputs[i]
device_mem = cuda.mem_alloc(host_mem.nbytes)
# Append the device buffer to device bindings.
bindings.append(int(device_mem))
# Append to the appropriate list.
shape = (real_size, *engine.get_binding_shape(binding)[1:]) if not trt_inputs else trt_inputs[i].shape
if engine.binding_is_input(binding):
inputs.append({'host': host_mem, 'device': device_mem, 'shape': shape})
else:
outputs.append({'host': host_mem, 'device': device_mem, 'shape': shape})
stream = cuda.Stream()
for i in range(len(inputs)):
context.set_binding_shape(i, inputs[i]['shape'])
[cuda.memcpy_htod_async(inp['device'], inp['host'], stream) for inp in inputs]
context.execute_async_v2(bindings=bindings, stream_handle=stream.handle)
[cuda.memcpy_dtoh_async(out['host'], out['device'], stream) for out in outputs]
stream.synchronize()
print(outputs)
return real_size, [out['host'] for out in outputs]
with engine.create_execution_context() as context:
t = time.time()
batch_size, trt_outputs = allocate_buffers_and_inference(context, engine, trt_inputs=None)
print('trt infernce average %dms' % ((time.time() - t) * 1000 / batch_size))四、pycuda编程和django uwsgi部署
stream = cuda.Stream()
for i in range(len(inputs)):
context.set_binding_shape(i, inputs[i]['shape'])
[cuda.memcpy_htod_async(inp['device'], inp['host'], stream) for inp in inputs]
# trt context
context.execute_async_v2(bindings=bindings, stream_handle=stream.handle)
[cuda.memcpy_dtoh_async(out['host'], out['device'], stream) for out in outputs]
stream.synchronize()cuda也有context的概念,主要负责gpu运算以及gpu和cpu之间的数据交换。
新建cuda context的花销比较大,所以在后端要使用pop和push方法隐藏和激活
import pycuda.driver as cuda
ctx = cuda.Device(0).make_context()
# 调用pop和push方法隐藏和激活
cuda.push()
cuda.pop()五、最后
测试tensorrt花销为20ms,正常gpu速度为30ms,提升了50%。如果是一些v100或者a100这样的专业显卡的话提升会更多。