一、预训练+对比学习=SOTA句向量?
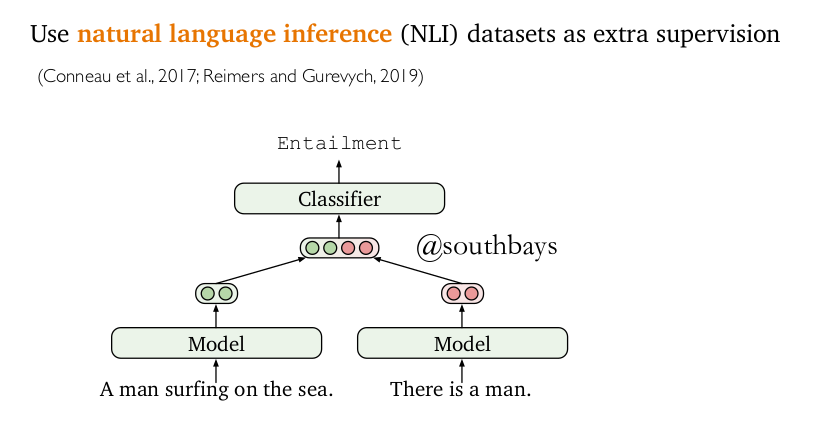
- Contracdiction pairs of NLI(自然语言推理)
先看nli推理是将句子对输出两次句向量,并计算其相似度。
Pretraining model(预训练模型)
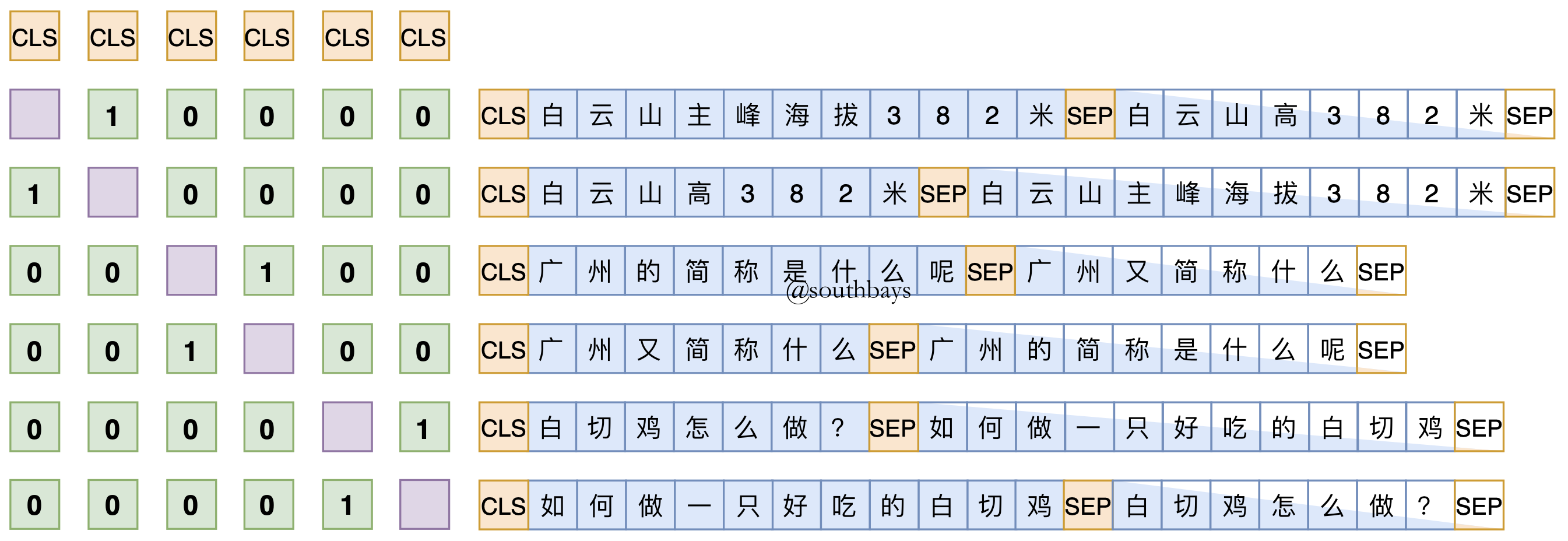
再看一个利用bert的[CLS]标签编码两两作点积来训练相似度(主要看左侧矩阵,来自苏剑林的simbert)。
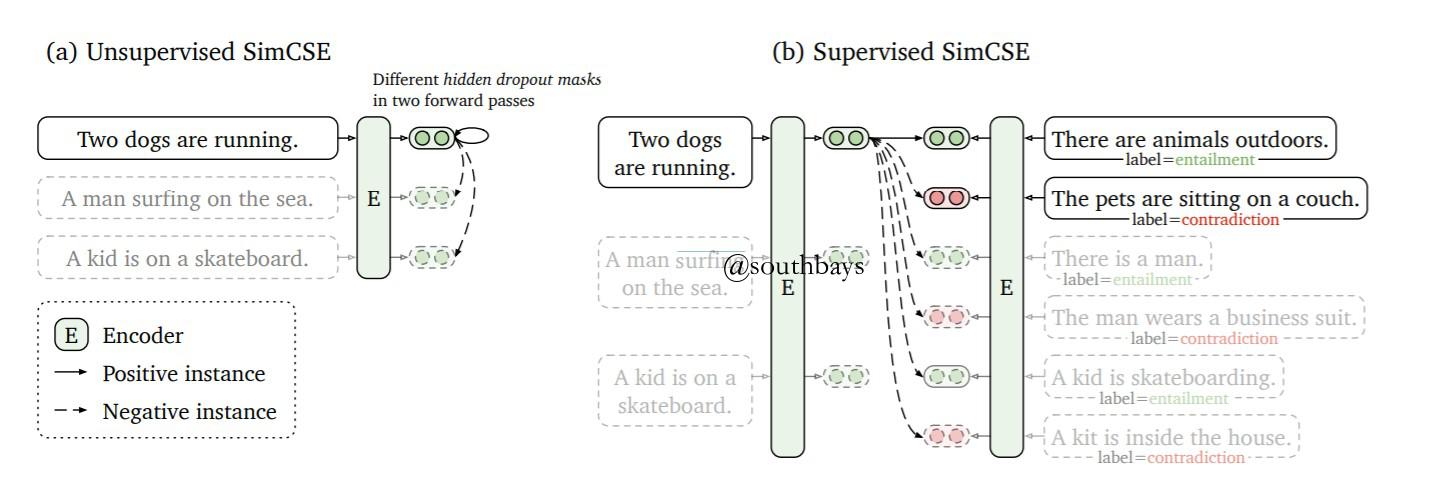
第一个方法是构造相似或者不向似的句子对,预测0和1的标签,是一个有监督学习
第二个方法可以用于无监督学习。在一个batch的n个句子中,自己作为正例,除了自己以外的其它句子都作为负例,最后生成一个nn的相似度矩阵,预测的目标就是一个nn的单位矩阵SimCSE就是融合了两种方法,它的正例是对自己重复编码dropout生成的不同向量(后面会具体解释),负例是是其它句子重复编码生成的向量,同样生成一个n*n的相似度矩阵。
二、原理
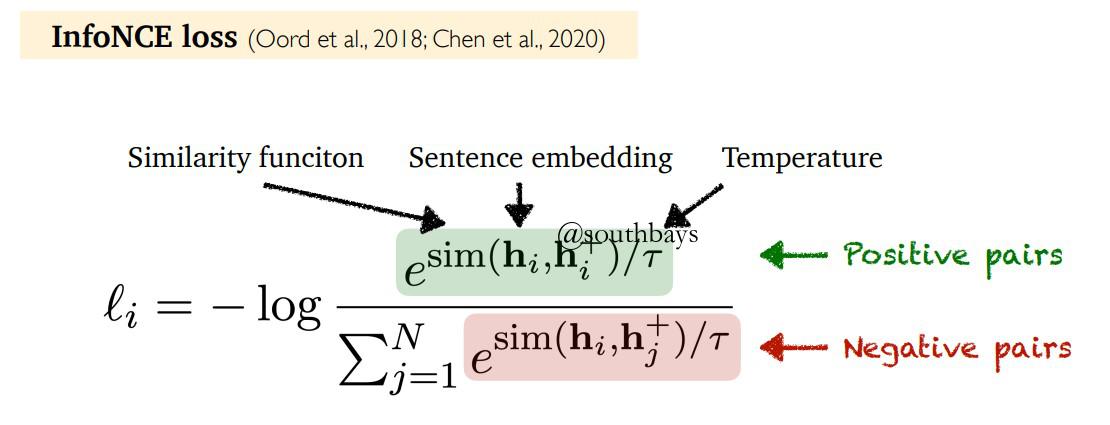
info NCE loss
stand dropout vs other data augmentation
SimCSE (dropout)NLP is interesting. —— NLP is interesting.Next sentenceI do NLP. —— NLP is interesting.Synonym replacementThe movie is great. —— The movie is fantastic.cropsTwo dogsare running. ——Twodogs arerunning.Delete one wordTwo dogs arerunning. —— Two dogsarerunning.
三、深层原因?
alignment vs. uniformity(PaperOrigin) (PaperLocal)

alignment:正样本的对齐性
uniformity:所有样本分布的一致性对SimCSE等方法定量分析训练过程中的对齐性和一致性
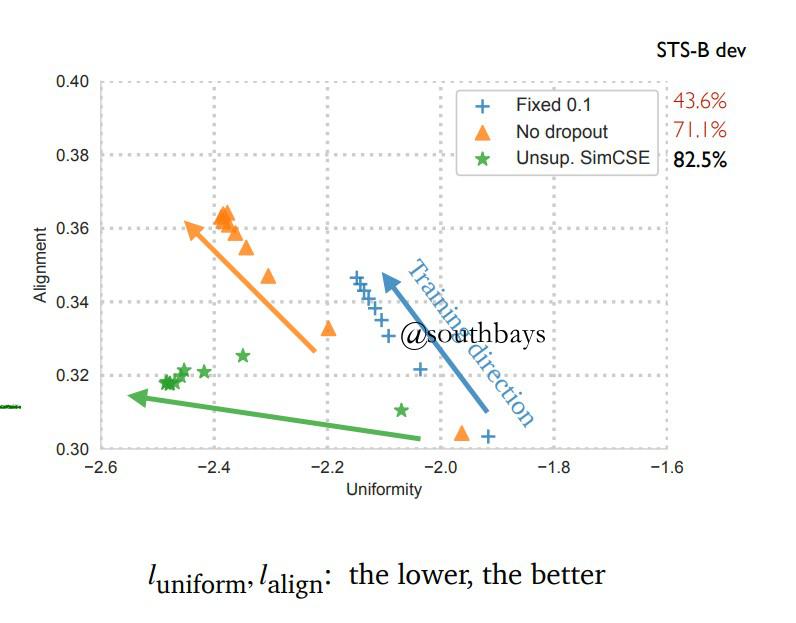
SimCSE表现最好,在提升一致性的同时很好的保持了对齐性
四、思考:
- bert的原始的[CLS]向量不可靠
- 前置研究句向量的降维-bert whitening也印证了[CLS]向量包含较多的冗余信息,当然,whitening最主要的作用还是将句向量转化到标准正交基上,从而更好地使用余弦相似度
(PaperOrigin) (PaperLocal)
博客地址
一个线性变换-PCA降维可以把维度从768降到256,1024降到384而保持差不多的结果。 - SimCSE可以处理的文本更长,因为句子对是分别编码的,而降维思想可以在储存和检索向量时大大减少空间和内存的占用从而提升检索效率
- 应用场景1. 实体链接
- 应用场景2. 文本聚类
- 应用场景3. 问句检索